-- SYSDTE 예제
SELECT TO_CHAR(SYSDATE,'RRRR-MM-DD HH24:MI:SS') "지금시간"
FROM DUAL ;
SELECT TO_CHAR(SYSDATE-1,'RRRR-MM-DD HH24:MI:SS') "하루전지금시간"
FROM DUAL ;
SELECT TO_CHAR(SYSDATE-1/24,'RRRR-MM-DD HH24:MI:SS') "1시간전시간"
FROM DUAL ;
SELECT TO_CHAR(SYSDATE-1/24/60,'RRRR-MM-DD HH24:MI:SS') "1분전시간"
FROM DUAL ;
SELECT TO_CHAR(SYSDATE-1/24/60/10,'RRRR-MM-DD HH24:MI:SS') "6초전시간"
FROM DUAL ;
SELECT TO_CHAR(SYSDATE-(5/24 + 30/24/60 + 10/24/60/60),'RRRR-MM-DD HH24:MI:SS') "5시간 30분 10초전"
FROM DUAL ;
[SYSTIMESTAMP를 통해 현재시간, MONTH, HOUR, MINUTE 전 시간 구하기]
-- SYSTIMESTAMP
-- SYSTIMESTAMP 함수를 사용하면 현재 일자와 시간(시스템기준)을 얻을 수 있다.
-- SYSTIMESTAMP 예제
SELECT TO_CHAR(SYSTIMESTAMP,'RRRR-MM-DD HH24:MI:SS.FF3')
FROM DUAL ;
SELECT TO_CHAR(SYSTIMESTAMP,'RRRR-MM-DD HH24:MI:SS.FF9')
FROM DUAL ;
SELECT TO_CHAR(SYSTIMESTAMP -1/24,'RRRR-MM-DD HH24:MI:SS') "1시간전시간"
FROM DUAL ;
SELECT TO_CHAR(SYSTIMESTAMP -1/24/60,'RRRR-MM-DD HH24:MI:SS') "1분전시간"
FROM DUAL ;
[내가 살아온 개월 수, 일수]
--Q1. 내가 살아온 월 수 or 일 수
SELECT MONTHS_BETWEEN(TO_DATE(SYSDATE, 'RRRR-MM-DD'),
TO_DATE('2000-01-01', 'RRRR-MM-DD')) AS "내가 살아온 월 수"
FROM DUAL;
SELECT TRUNC(MONTHS_BETWEEN(TO_DATE(SYSDATE, 'RRRR-MM-DD'),
TO_DATE('2000-01-01', 'RRRR-MM-DD')),1) AS "내가 살아온 월 수"
FROM DUAL;
SELECT TO_DATE(SYSDATE, 'RRRR-MM-DD') -
TO_DATE('2000-01-01', 'RRRR-MM-DD') as "내가 살아온 날 수"
FROM DUAL;
■ 집계 함수
함수
내용
AVG() (평균)
평균 값을 반환
COUNT() (개수)
검색된 행의 수
MAX() (최대값)
컬럼값 중에서 최대값을 반환
MIN() (최소값)
컬럼값 중에서 최소값을 반환
SUM() (합계)
검색된 컬럼의 합을 반환
STDDEV()
표준변차 반환
■ NULL과 관련된 함수
함수
내용
NVL(필드, 대체값)
NULL이면 대체값 대입 (NULL이 아니면 그대로 사용)
NVL2(필드, 참값 ,거짓값)
NULL이 아니면 참값, NULL이면 거짓값
CREATE TABLE MEMBER
(
DEPTNO NUMBER(5),
NAME CHAR(3 CHAR),
RECDATE DATE,
SECTOR VARCHAR2(100)
)
SELECT
NAME, RECDATE,
NVL(SECTOR, '미지정') AS SECTOR,
NVL2(SECTOR, '지정 완료', '미지정') AS SECTOR
FROM MEMBER
- 산술을 제외하고, 관계/논리/기타 모두 문자열에 사용 가능하다. **산술은 문자열에 사용 불가하다.
연산자
코드
산술 연산자
+ - * / mod(피젯수, 젯수)
관계 연산자
> >= < <= =(동일한가) !=(동일하지 않음) <> (동일하지 않음) **null을 체크할 때는, 필드 is null 필드 is not null 을 사용한다.
논리 연산자
and or not 필드 between A and B (A이상 B이하) 필드 in (A, B, C)필드=A or 필드=B or 필드=C
패턴 비교 연산자
LIKE, %, _
* 오라클은 정수, 실수 개념이 없어서, 10/3은 실수로 나온다.
* mod(x,y) --> 나머지 구하는
* dual은 오라클에서 기본적으로 제공하는 테이블이다.
* XML에서 < > 태그 사용하므로 >= ~ <= 보다, between을 쓰는게 좋다.
* 가급적 not( ) 역조건은 사용하지 않는 것이 좋다. -- why? SELECT를 두 번 하기 때문에 속도 저하
■ 기본 필드와 연산 필드
--heading : select의 결과로 추출된 임시 컬럼명
--연산 필드 : 기본 필드의 연산에 의해서 형성된 필드
select
sabun as 사번, -- 기본 필드
saname 사원명, -- as 생략가능
--sajob as 직 급, -- 에러! 공백을 띄어서 표준명명법에 어긋남
sajob as "직 급", -- OK
sapay,
sapay * 0.1 as bonus -- 연산 필드
from sawon
■ 문자의 결합 ||
select (문자데이터)칼럼명 || '추가하고자 하는 문자열' from 테이블명
■ 패턴 비교 연산자 : LIKE, %, _
[1] % (나 다음 모든문자)
select * from 테이블
where (문자데이터)칼럼명 like '김%' -- 맨앞글자가 김인 데이터(그 뒤는 길이도 상관없음)
[2] _ (모든 문자에서 1개)
select * from 테이블
where (문자데이터)칼럼명 like '____-1%'
-- 앞에 6글자는 아무것이나 와도 되나, 그 뒤는 '-1'이 오는 데이터만 추출
■ 정규식을 이용한 패턴 비교(REGEX_LIKE)
정규식은 차후에 업로드 예정
▼ 연산자 예시 *출처 : 뉴렉처
[1] 산술 연산 / 문자열 결합 예시
--덧셈은 숫자만 더하기 때문에 숫자 + 문자면 숫자로 더해진다
SELECT 1+'3' FROM DUAL;
--문자와 문자를 더하기
SELECT 1 || '3' FROM DUAL;
--Q. 모든 회원의 이름을 조회하시오. 단 이름은 ID를 붙여서
SELECT NAME || '(' || ID || ')' "이름(ID)" FROM MEMBER;
>> 마지막 Q결과
[2] 비교연산자 예시
-- 게시글 중에서 작성자가 '홍길동'인 게시글만 조회
SELECT * FROM NOTICE WHERE WRITER_ID = '홍길동';
-- 게시글 중에서 조회수가 100이 넘는 글만 조회
SELECT * FROM NOTICE WHERE HIT > 100;
-- 게시글 중에서 내용을 입력하지 않은 게시글을 조회
-- ★ NULL의 경우 = 연산자 사용 불가. 반드시 IS를 써야한다.
SELECT * FROM NOTICE WHERE CONTENT IS NULL;
[3] 논리연산자 예시
-- 조회수가 0, 1, 2인 게시글을 조회하시오.
SELECT * FROM NOTICE WHERE HIT IN (0, 1, 2);
SELECT * FROM NOTICE WHERE HIT = 0 OR HIT = 1 OR HIT = 2;
SELECT * FROM NOTICE WHERE HIT BETWEEN 0 AND 2;
SELECT * FROM NOTICE WHERE 0 <= HIT AND HIT <= 2;
--조회수가 0, 2, 7인 게시글을 조회하시오.
SELECT * FROM NORICE WHERE HIT IN (0, 2, 7);
SELECT * FROM NOTICE WHERE HIT = 0 OR HIT = 2 OR HIT = 7; -- 비효율적
--조회수가 0, 2, 7이 아닌 게시글을 조회하시오.
SELECT * FROM NOTICE WHERE HIT NOT IN(0, 2, 7);
[4] 패턴 비교 연산자 예시
-- 회원 중에서 '박'씨 성을 조회하시오
SELECT * FROM MEMBER WHERE NAME = '박%'; -- 박% 이라는 문자를 찾는다
SELECT * FROM MEMBER WHERE NAME LIKE '박%';
-- 회원 중에서 '박'씨이고 이름이 외자인 회원을 조회하시오.
SELECT * FROM MEMBER WHERE NAME LIKE '박_';
-- 회원 중에서 '박'씨 성을 제외한 회원을 조회하시오.
SELECT * FROM MEMBER WHERE NAME NOT LIKE '박%';
-- 회원 중에서 이름에 '도'자가 들어간 회원을 조회하시오.
SELECT * FROM MEMBER WHERE NAME LIKE '%도%';
SutdaDeck() {
//1~20까지 1-10순으로 숫자 초기화 **숫자가 1,3,8의 경우 둘 중 하나는 광
int num = 1;
for (int i = 0; i < CARD_NUM; i++) {
if (i == 10) num = 1;
if (i+1 == 1 || i+1 == 3 || i+1 == 8) {
cards[i] = new SutdaCard(num++,true);
}else {
cards[i] = new SutdaCard(num++,false);
}
}//end for
}//SutdaDeck()
[남궁성님 풀이]
for (int i = 0; i < cards.length; i++){
//숫자를 넣어줄 변수
int num = i % 10 + 1; //i가 0일때 > 1, i가 1일때 >2...i가 10일때 > 1
boolean isKwang = (i < 10) && (num == 1 || num == 3 || num == 8);
cards[i] = new SutdaCard(num, isKwang);
}
엄청나게 간결해진 코드. 객체 생성자의 매개변수에 연산식을 줌으로써 코드를 확 줄였다.
▶ 내가 잡고 가야할 점 : 복잡한 조건문을 쓰기 보다, 변수 자체에 연산식을 사용하는 법을 먼저 고려해보자.
package _07_객체지향프로그래밍2;
class SutdaDeck2{
final int CARD_NUM = 20;
SutdaCard2[] cards = new SutdaCard2[CARD_NUM];
SutdaDeck2() {
//문제 7_1 정답
}//SutdaDeck()
//(1) 정의된 세개의 메서드 작성
}
class SutdaCard2{
int num;
boolean isKwang;
SutdaCard2(){
this(1,true);
}
SutdaCard2(int num, boolean isKwang){
this.num = num;
this.isKwang = isKwang;
}
@Override
public String toString() {
return num + (isKwang? "K":"");
}
}
public class EX7_2 {
public static void main(String[] args) {
SutdaDeck deck = new SutdaDeck();
System.out.println(deck.pick(0));
System.out.println(deck.pick());
deck.shuffle();
for(int i=0; i < deck.cards.length;i++)
System.out.print(deck.cards[i]+",");
System.out.println();
System.out.println(deck.pick(0));
}
}
class MyTv2 {
private boolean isPowerOn;
private int channel;
private int volume;
final int MAX_VOLUME = 100;
final int MIN_VOLUME = 0;
final int MAX_CHANNEL = 100;
final int MIN_CHANNEL = 1;
public void setIsPowerOn(boolean isPowerOn){
this.isPowerOn = isPowerOn;
}
public boolean getIsPowerOn() {
return this.isPowerOn;
}
public void setChannel(int channel) {
this.channel = channel;
}
public int getChannel() {
return this.channel;
}
public void setVolume(int volume) {
this.volume = volume;
}
public int getVolume() {
return this.volume;
}
}//end class
[남궁성님 풀이]
-- 정말 private과 getter setter만 만드는데 치중하느라 MIN과 MAX를 설정할 생각을 안했다. 함정이네 함정이야.ㅠ 그런데 현장에서도 늘 이렇게 범위를 고려해야하는 건 맞기에.. 앞으로 생각의 생각을 더 해야겠다.
기본키 *기본키로 설정된 도메인에 not null + unique + index 제약이 자동 설정
키 무결성
foreign key
외래키 *현재 입력(수정) 값의 유효성을 외부 데이블 부모키(컬럼)을 참조해서 체크
참조 무결성
★ 무결성의 종류
1.널 무결성 :릴레이션의 특정속성 값이 Null이 될 수 없도록 하는 규정 *릴레이션 = 테이블 2. 고유 무결성 :릴레이션의 특정 속성에 대해서 각 튜플이 갖는 값들이 서로 달라야 한다는 규정 3. 참조 무결성 :외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 한다는 규정 즉 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다는 규정 4. 도메인 무결성 :특정 속성의 값이, 그 속성이 정의된 도메인에 속한 값이어야 한다는 규정 5. 키 무결성 :하나의 테이블에는 적어도 하나의 키가 존재해야 한다는 규정
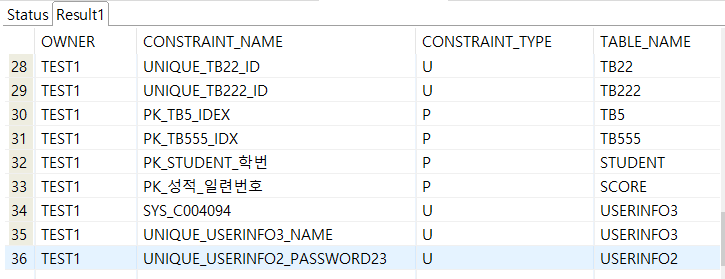
■ 제약조건 조회 - 딕셔너리에서 조회
※ 유의할 점! 딕셔너리 내의 모든 정보는 대문자로 저장된다.
따라서, where문을 통해 특정 테이블을 지정할 때는 꼭 upper(' ')를 쓰도록 하자.
[1] CMD에서 아래와 같이 제약조건에 관한 데이터들 확인
desc user_constraints
>> 결과
[2] 찾고자 하는 정보에 대한 명령어 입력
select owner, constraint_name, constraint_type, table_name from user_constraints
>> 결과
[3] 특정 테이블에 대한 정보만 뽑아서 보기
select owner, constraint_name, constraint_type, table_name from user_constraints
where table_name = upper('userInfo3')
>> 결과
■ 제약조건 생성
[방법1] 테이블 생성 시 제약에 대한 명칭 없이 조건만 다는 방법
create table userInfo
(
name varchar2(100) not null,
nickname varchar2(100) null
)
/
[방법2] 테이블 생성 시 제약에 대한 명칭과 함께 조건을 다는 방법
create table userInfo2
(
name varchar2(100) not null,
id varchar2(100) not null unique,
password varchar2(100) not null,
constraint unique_userInfo2_password unique(id)
)
/
[방법3] 테이블 생성 후 제약에 대한 명칭과 함께 조건을 다는 방법 ** 가장 많이 사용되는 코드이다.
create table userInfo3
(
name varchar2(100) not null,
id varchar2(100) not null unique,
password varchar2(100) not null
)
/
alter table userInfo3
add constraint unique_userInfo3_password unique(password);
create table userInfo3
(
name varchar2(100) not null,
id varchar2(100) not null unique,
password varchar2(100) not null
)
alter table userInfo3
add constraint unique_userInfo3_password unique(password);
insert into userInfo3 values('홍길동','hong123','1234'); -- OK
insert into userInfo3(name) values('나길동'); -- 에러! 데이터 미삽입 : 널 무결성 위배
--ORA-01400: NULL을 ("TEST1"."USERINFO3"."ID") 안에 삽입할 수 없습니다
insert into userInfo3 values('다길동','hong123','2345'); -- 에러! 중복값 추가 : 고유 무결성 위배
-- ORA-00001: 무결성 제약 조건(TEST1.SYS_C004094)에 위배됩니다
위 코드를 이클립스에서 하나씩 [ALT]+[X]해서 실행해보면 먼저, 아래와 같이 에러 메세지가 나타난다.
ORA-01400: NULL을 ("TEST1"."USERINFO3"."ID") 안에 삽입할 수 없습니다
그 다음으로 나타나는 에러 메세지는 아래와 같은데, unique로 id에 중복을 불허했는데 중복된 id를 넣어버렸다는 의미
CHECK
- 문법
alter table 테이블명
add constraint 제약조건명 check(조건절)
- 실제 코드
alter table userInfo3
add constraint check_userInfo3_mat check(mat between 0 and 100)
DEFAULT
- 문법
alter table 테이블명
modify 칼럼헤딩 타입 default 'UNKNOWN'
- 실제코드
alter table userInfo3
modify name varchar2(100) default 'UNKNOWN'
Primary Key
※ 기본키를 지정해주면 해당키 칼럼에 not null과 unique제약이 걸리며, 해당키 칼럼은 테이블의 index가 된다.
※ 모든 테이블은 키 무결성 원칙을 지키기 위해 최소 1개의 primary key를 가지고 있다.
[1] 하나의 키를 지정하는 방법
- 문법
alter table 테이블명
add constraint 제약조건명 primary key(칼럼명);
- 실제코드
alter table tb5
add constraint pk_tb5_idx primary key(idx);
-- 원본 테이블 ) userInfo3
create table userInfo3
(
SID int,
name varchar2(100) not null,
id varchar2(100) not null unique,
password varchar2(100) not null,
eng int check(eng between 0 and 100),
mat int check(mat between 0 and 100)
)
alter table userInfo3
add constraint pk_userInfo3_SID primary key(SID)
insert into userInfo3 values(1001, '김길동', 'kim1234', '1234', 88, 100);
insert into userInfo3 values(1002, '나길동', 'nah1234', '2345', 78, 90);
insert into userInfo3 values(1003, '다길동', 'dah1234', '2345', 98, 50);
select * from userInfo3
>> 결과
[A테이블 : userInfoRevised1]
-- A테이블 ) userInfoRevised1
create table userInfoRevised1
(
SID int,
name varchar2(100) not null,
id varchar2(100) not null unique,
password varchar2(100) not null
)
alter table userInfoRevised1
add constraint pk_userInfoRevised1_SID primary key(SID)
insert into userInfoRevised1 values(1001, '김길동', 'kim1234', '1234');
insert into userInfoRevised1 values(1002, '나길동', 'nah1234', '2345');
insert into userInfoRevised1 values(1003, '다길동', 'dah1234', '2345');
select * from userInfoRevised1
>> 결과
[B테이블 : userInfoRevised2]
-- B테이블 : userInfoRevised2
create table userInfoRevised2
(
idx int,
SID int,
name varchar2(100) not null,
eng int check(eng between 0 and 100),
mat int check(mat between 0 and 100)
)
alter table userInfoRevised2
add constraint pk_userInfoRevised2_idx primary key(idx)
alter table userInfoRevised2
add constraint fk_userInfoRevised2_SID foreign key(SID) references userInfoRevised1(SID)
insert into userInfoRevised2 values(1, 1001, '김길동', 88, 100); -- OK
insert into userInfoRevised2 values(2, 1002, '나길동', 78, 90); -- OK
insert into userInfoRevised2 values(3, 1005, '다길동', 98, 50); -- 에러! 없는 SID 코드
CREATE TABLE MEMBER
(
ID VARCHAR2(50),
PWD VARCHAR2(50),
NAME VARCHAR2(50),
GENDER CHAR(50),
AGE NUMBER,
BIRTHDAY CHAR(50),
PHONE CHAR(50),
REGDATE DATE
)
DROP TABLE MEMBER;
-- 1. 자료 타입 변경
-- 기존 데이터가 10보다 넘어가는 게 있으면 크기 수정이 안된다.
ALTER TABLE MEMBER MODIFY ID VARCHAR2(10);
-- 2. 칼럼 삭제
ALTER TABLE MEMBER DROP COLUMN AGE;
-- 3. 행 추가
ALTER TABLE MEMBER ADD EMAIL VARCHAR2(200);
■ DML(Data Manipulation Language) : DB의 데이터를 생성/조회/갱신/삭제하는 언어
- CRUD의 개념 : Create(생성), Read(=RETRIEVE읽기/조회), Update(갱신), Delete(삭제)
- 데이터는 일반적으로 CRUD방식을 통해 관리된다.
INSERT
삽입 *테이블에 삽입한다는 개념으로 INSERT 사용
SELECT
조회 *테이블에서 특정 데이터를 뽑아서 본다는 개념으로 SELECT 사용
UPDATE
갱신
DELETE
삭제
[1] INSERT __ * 코드 원본 출처 : 뉴렉쳐 강의
CREATE TABLE MEMBER
(
ID VARCHAR2(50),
PWD VARCHAR2(50),
NAME VARCHAR2(50),
GENDER CHAR(50),
AGE NUMBER,
BIRTHDAY CHAR(50),
PHONE CHAR(50),
REGDATE DATE
);
-- 대문자를 주로 사용. (대소문자 구분x) / 다만 비교를 할 때는 소문자 사용
INSERT INTO MEMBER(ID, PWD) VALUES('NEW LEC','111');
INSERT INTO MEMBER(ID, PWD) VALUES('DRAGON','111');
SELECT id, name, pwd FROM MEMBER;
-- " " 안에 임시 헤딩을 사용하면 대문자로 변환되지 않고 소문자를 그대로 출력한다.
SELECT id "user_ID", NAME, PWD FROM MEMBER;
[2] UPDATE __ * 코드 원본 출처 : 뉴렉쳐 강의
CREATE TABLE MEMBER
(
ID VARCHAR2(50),
PWD VARCHAR2(50),
NAME VARCHAR2(50),
GENDER CHAR(50),
AGE NUMBER,
BIRTHDAY CHAR(50),
PHONE CHAR(50),
REGDATE DATE
);
INSERT INTO MEMBER(ID, PWD) VALUES('NEW LEC','111');
INSERT INTO MEMBER(ID, PWD) VALUES('DRAGON','111');
-- 모든 PWD 데이터가 '222'로 바뀐다.
UPDATE MEMBER SET PWD = '222';
UPDATE MEMBER SET PWD = '222' WHERE ID = 'newlec';
-- 문자 데이터의 경우 대소문자를 구분하기 때문에 대소문자까지 일치해야한다.
UPDATE MEMBER SET PWD = '333', name = '손오공' WHERE ID = 'DRAGON';
[긴 코드 예시_테이블 생성/수정/삭제 & 데이터 CRUD]
create table scores
(
--변수명 자료형
--//크기는 넉넉하게 준다.
name varchar2(100), --byte단위 가변길이
kor number(5), --숫자의 길이 단위
eng int,
mat number(5,1),
prev char(4) --byte단위 고정길이
)
/
--////////////////////////////////////////////////////////////////////--
-- DML(Data Manipulation Language) : insert update delete select(CRUD)
--데이터 삽입 - insert into ~~ values ();
insert into scores values('김길동',80,80.5,80.5,'A');
insert into scores values('나길동',90,95,100,'B');
insert into scores values('다길동',75,23,55,'C');
insert into scores values('라길동',88,55.5,60,'A'); --int형에 55.5를 넣으면 반올림이됨
insert into scores(name,kor,eng) values('바길동',99,100);
--데이터 조회 - select ~~ from ~~~
select * from scores
select
name, kor, eng, mat, prev
from scores
select
name, kor
from scores
select
name, kor, eng, mat, prev,
(kor+eng+mat)/3 as avg
from scores
select
name, kor, eng, mat, prev,
rank() over(order by (kor+eng+mat) desc) as rank
from scores
-- 데이터 갱신 - update ~~ set ~~~ where ~~~
update scores set kor = 10; -- <<모두 갱신
update scores set kor = 85 where name = '나길동'
update scores set eng = 90 where name = '라길동'
update scores set name = '마길동' where name = '다길동';
update scores set name = '다길동' where name = '라길동';
-- 데이터 삭제 - delete ~~ from ~~~ where ~~~
delete from scores --전체 데이터 삭제
delete from scores where name = '바길동'
delete from scores where 1 = 1; -- 전체 데이터 삭제
--///////////////////////////////////////////////////////////////////--
-- DDL(Data Definition Language) : create(생성), drop(삭제), alter(수정)
-- 테이블 수정
-- 1. 칼럼 추가
-------------칼럼 추가시 이슈사항 : 칼럼을 추가하면 이전의 연산식을 수정해야한다.(사전 데이터 설계의 중요성)
alter table scores add sci int;
alter table scores add commt varchar2(600); --최대 200글자
update scores set sci = 100, commt = '잘했어요.';
select * from scores
-- 2. 칼럼 삭제
alter table scores drop column prev;
-- 테이블 삭제
drop table scores;
> 고정 길이는 가변 길이 보다 검색 속도가 더 빠르다. (왜냐면, CHARACTER는 구분자를 통해 구분되기 때문)
> 가급적 고정적인 데이터는 VARCHAR2( ) 보다 CHAR을 사용하는 것이 좋다.
> 오라클에서 기본적으로 AL32UTF8 인코딩 방식 사용 [한 글자에 3BYTE]
-VARCHAR2(SIZE[BYTE | CHAR])는 가변 길이이다.
> 지정해둔 사이즈만큼 메모리 공간을 쓰는 것이 아니며, 실제 저장한 문자 크기 만큼만 메모리 공간을 사용한다.
- NCHAR(SIZE)
> 세계 각국의 문자를 사용할 수 있는 데이터 형태.
> 오라클에서 기본적으로 AL16UTF16 인코딩 방식 사용 [한 글자에 2BYTE]
> 고정 길이 문자이면서, 세계 각국 언어(그 중에 한글도 포함)을 쓸 경우엔 NCHAR을 쓰는게 효율적이다.
- NVARCHAR2(SIZE)
CREATE TABLE MEMBER
(
ID VARCHAR2(50),
PWD NVARCHAR2(50),
NAME NVARCHAR2(50),
----GENDER CHAR(6), --- 남성, 여성, 기타 // 6 BYTE로 지정
----GENDER CHAR(2 CHAR), --- 2 뒤에 CHAR 선택
GENDER NCHAR(2), --- 2 뒤에 CHAR 지정x >> 2 글자라는 의미
AGE NUMBER,
BIRTHDAY CHAR(50), --- 2000-03-05 고정길이
PHONE CHAR(13), --- 010-123-2345 고정길이
REGDATE DATE
)
SELECT LENGTH('한글') FROM DUAL; --- 결과 : 2
SELECT LENGTHB('AB') FROM DUAL; --- 결과 : 2 << 2바이트
SELECT LENGTHB('한글') FROM DUAL; --- 결과 : 6
--문자 환경설정 확인
SELECT * FROM NLS_DATABASE_PARAMETERS; -- NCHAR은 한글 한글자에 2BYTE사용
[문자도 정렬이 될까?]
※ 문자도 SORTING이 된다 (A,B,C,D,.... 숫자면 1, 2, 3, 4....) - 아래와 같이 날짜 타입의 데이터를 문자로 변환 후 그 문자의 최소값을 구하는 게 가능하다.
SELECT * FROM sawon WHERE TO_CHAR(sahire,'YYYY-MM-DD') = (SELECT MIN(TO_CHAR(sahire,'YYYY-MM-DD')) FROM sawon)
3. 간단 sql 명령어
간단 sql 명령어 정리
■ 로그인 sqlplus host/password
■ 연결 connect scott/tiger
■ 현재 사용자 출력 show user
■ 테이블 구조 설명 출력 describe tab 또는 desc tab
■ 잠깐 cmd으로 넘어가기 host >> 잠시 cmd로 이동 exit >> 다시 sql로 넘어감
■ SQL 나가기 exit
4. 메모장으로 sql파일 저장 후, CMD에서 실행하기
[1] SQL파일 저장
※ 유의사항 : 사전에 sql파일을 저장할때 인코딩 charset을 ANSI로 설정 why? OS운영체제에 따라 사용하는 인코딩이 다르기 때문(ex. window - MS949)
[2] SQL파일 실행하기 1. cmd에서 sql파일 위치로 cd 경로 이동 2. sqlplust host/password 접속
3. @a로 파일 실행 ※ 에러 : 단일 인용부를 지정해 주십시오 << 인코딩이 맞지 않아서다.(파일을 재저장하면 된다)
※ 이건 10g 버전의 경우에만 가능하며, 아래와 같은 방식은 DBO관리자가 주로 사용하기 용이
http://127.0.0.1:8080/apex
[방법2] CMD창에서 클라이언트 도구 sqlplus.exe 통해 접속하기
sqlplus.exe 계정/암호
[방법3] 이클립스에서 접속하기
※ 사용자는 이미 생성된 상태
새로운 Database connection를 만들거다내가 등록했던 정보 작성후 [Test Connection] 하기 *xe는 오라클 버전이다.사용자 선택 후 오른쪽 마우스하여 Connect를 누른다.이클립스 상단에서 [1] 내 오라클 버전 [2] 사용자명 [3] Databse를 선택한다.
[방법4] 외부 클라이언트 도구 - ex. SQL developer
■ 전체 사용자 조회하기
//모든 사용자 관련 정보를 설명하라
desc all_users
//모든 사용자들 데이터들을 출력하라
select * from all_users;
■ 이클립스와 오라클 DBMS를 연결하기
[상황1] 서버가 내 컴퓨터(로컬)에 있을 때 == localhost 사용할 때
- 작업 1. (선택사항) 계정 하나 만들기 *이미 계정이 있다면 연결만 하기
※ 여기서는 기존에 있는 hr 계정 활성화하는 것으로 대체
[1] 데이터베이스 로그인 후 HR(임시계정) 잠금 풀기 localhost:8080/apex > 관리 > 데이터베이스 사용자 > 비밀번호(1234등 아무거나) > HR잠금 풀기 설정 후 확인
[2] 로그아웃 후 HR로 로그인하여 객체 브라우저로 이동
- 작업 2. 오라클 driver파일을 작업 프로젝트로 이동시키기
[1] 오라클's이클립스 연결 파일(driver) 경로로 이동 C:\oraclexe\app\oracle\product\10.2.0\server\jdbc\lib
[2] driver파일을 프로젝트 취상위 경로에 복사하여 이동 ex. OracleStudy폴더에 이동
- 작업 3. 이클립스에서 경로 설정
[1] perpective를 JavaEE로 설정 *JDK 다운시, java SE로 다운받으면 이 설정X
[2] 하단의 [Data Source Explorer] 탭 > [Database Connection] 폴더 선택 후 마우스 오른쪽 > new
[3] [New Connection Profile] 윈도우창 설정 후 [NEXT] - Connection Profile Types : Oracle 선택 - Name : Oracle_DBO이름 설정 *아무 이름이나 괜찮음. 한글도 상관 없음. ex) Oracle_hr
[4] [New Connection Profile] 윈도우창에 테이블 나타남 - Drivers 셀렉박스 바로 옆 아이콘 선택, [New Driver Definition] 윈도우창으로 이동
[5] [New Driver Definition] 윈도우창에서 아래와 같이 설정 후 [OK] - [Name/Type] Oracle Thin Driver의 나의 오라클 버전(10) 선택 - [JAR List] 작업2의 [2]에서 옮긴 파일 경로로 경로 변경
[6] [New Connection Profile]으로 재이동 후 Properties 작성 후 [Test Connection] 선택 --> Ping succeeded! 하면 정상연결된 것 - Service Name : xe ***사용하는 오라클 버전 (Express Edition -- 교육용) - Host : localhost - User name : hr - Password : 1234 *save password 체크
[상황2]서버가 외부에 있을 때 - AWS클라우스 사용 가정
- 작업 1. (선택사항) 아마존에서 계정 생성 후 계정 정보를 획득한다. *이미 있다면 그것을 사용 * 보안 그룹 > 인바운드 규칙 편집 : 새 규칙 생성 rf. 예시) 유형(Oracle-RDS), 프로토콜(TCP), 포트 지정, 사용자는 Anywhere ---> 외부에서 접속 가능
- 작업 2. 오라클 드라이버 파일을 작업 프로젝트 폴더로 이동시킨다.
[참조 : 만약 드라이버 파일이 내 폴더 내에 없다면]
[1] mvnrepository.com로 이동
[2] 검색창에 ojdbc6 입력
[3] Files안의 jar파일을 다운
[1] 오라클's이클립스 연결 파일(driver) 경로로 이동 C:\oraclexe\app\oracle\product\10.2.0\server\jdbc\lib
[2] driver파일을 프로젝트 취상위 경로에 복사하여 이동 ex. OracleStudy폴더에 이동
- 작업 3. 이클립스에서 경로 설정
[1] [Data Source Explorer] 탭 > [Database Connection] > new - Name : Oracle_AWS_닉네임
[2] [New Connection Profile] - [Name/Type] Oracle Thin Driver의 나의 오라클 버전(10) 선택 - [JAR List] 작업2의 [2]에서 옮긴 파일 경로로 경로 변경 * 이미 등록된 드라이버라 할 경우, [Database Connection] 삼각형 아이콘 터치 > Driver수정 (다운받은 버전으로)