파이썬으로 만들어진 무료 오픈소스 웹 애플리케이션 프레임워크(web application framework)
웹 서버 요청이 오면, 장고 urlresolver가 url를 통해 경로를 파악하고, 요청사항을 view(함수 모음)에 전달하면, view가 함수를 통해 db에서 데이터 정보를 찾아, model 정보를 거쳐, template에 렌더링하는 방식으로 처리하는 프레임워크이다.
Django의 프로젝트와 앱 개념
- 프로젝트 : 내가 만들려고 하는 전체 프로젝트 - 앱 : 그 안에 들어가는 각각의 카테고리 또는 상위 기능들 (ex. 회원인증, 메신저 발송)
출처 https://dogfighterkor.tistory.com/4
Django의 MTV(Model, Template, View) 개념
- 모델 : 앱의 데이터와 관련된 부분 (DTO 또는 Entity의 개념) - 템블릿 : 사용자에게 보여지는 부분 (html) - 뷰 : 모델 데이터를 템블릿으로 전달하거나, 템플릿에서 발생하는 이벤트 처리 (요청 및 응답 처리) ㄴ 뷰는 다시 1) 클래스형 뷰, 2) 함수형 뷰로 나뉜다.
python3 --version # 파이썬 버전확인
python3 -m venv myvenv # 나의 가상환경 설정
#Mac
source myvenv/bin/activate # 맥은 bin 폴더를 통해 실행 가능
#Window
.\myvenv\Scripts\activate.bat # 윈도우는 Scripts 폴더를 통해 실행 가능
3. Django 설치
pip install django~={{파이썬 버전}}
Django 프로젝트 시작하기
1. Django 프로젝트 시작
django-admin startproject myweb . # myweb이라는 프로젝트로 시작 끝에 . 안 찍으면 안 됨
2. Django 프로젝트 내 App 설치 및 서버 실행해보기
python manage.py startapp aidiary # aidiary라는 app을 설치
python manage.py runserver # 서버 실행
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('aidiary.urls')),
]
모델 생성하기 - What is migration?
1. 마이그레이션 개념
마이그레이션 : 모델을 데이터베이스에 적용시키는 과정
> makemigrations : 모델의 생성 및 변경 사항에 대한 기록을 파일로 저장하는 것 -- ({{내 앱}}/migrations)에 저장됨 > migrate : makemigrations를 통해 생성된 파일을 실제로 실행하는 것
python manage.py migrate # 마이그레이트를 하겠다 = 모델을 DB에 반영하겠다
초반에 runserver를 하고 나면 이 migrate관련 에러가 뜨는데, 이는 모델에 대한 migrations를 안 해줬다는 경고였어요. 그래서 위 코드를 먼저 작성하면 해결할 수 있었습니다.
2. 어드민 페이지 들어가보기
아래의 코드를 통해서 수퍼 계정을 만들고 121.0.0.1:8000/admin 으로 들어가면 어드민 페이지가 나왔습니다. 거기서 데이터베이스에 대한 관리가 가능해요. 스프링과 다르게 DB 연동을 사전에 안 해도 어드민 페이지를 통해 테스트 과정에서 바로바로 데이터를 입출력할 수 있다는 게 정말 효율적이더군요.
python manage.py createsuperuser # 최상위 어드민 계정 생성
3. 모델 생성하기
App 폴더 하위에 보면 models.py가 있어요. 거기에 모델을 작성해주면 되는데 class 형태로 작성하고, django.db의 models를 사용합니다. Django도 스프링처럼 Orm을 사용해요. 하지만 스프링과 달리, django에서는 entity와 dto에 대해서 명시적인 구분을 따로 하지 않더라고요. (ex. @Table이나 @Entity를 통한 분리) 이 부분은 제가 좀 더 공부하면서 명시적인 구분을 하는 방법이 있는지 보려고 합니다.
이 기능이 진짜 좋은게, migrations 폴더 하위를 보면 변동사항이 생길 때마다 이렇게 무슨 짓(?)을 했는지가 기록으로 남아 있어요. 전체적인 수정사항을 확인할 수 있어서 좋다는 생각을 했습니다.
5. 모델 어드민 페이지에 적용하기
App 폴더 하위에 보면 admin.py 파일이 있어요. 거기에 위처럼 admin.site.register(Diary) 요렇게 생성한 모델을 적용해두면, 어드민 페이지에 Diary에 대한 CRUD 작업을 할 수가 있습니다.
본격적인 작업을 시작하기 전에
1. templates 폴더는 App 폴더 하위에 만들어주기
App 폴더 바로 아래에 templates 폴더를 만들고 그 안에 html 작업을 해주어야 정상적으로 view에서 경로를 찾을 수 있었어요.
2. models.py, urls.py 파일들이 없다면 각각 만들어주기
책에서는 models.py 외에도 forms.py를 따로 만들어주기도 했어요. 저는 처음에 models.py만 사용해보았는데, 상황에 따라 파일을 만들어주시면 될 것 같습니다.
모델 -> 템플릿 -> 뷰 -> Url 순서로 작업하기
책에 나와 있는대로 저는 모델 - 템플릿 - 뷰 - url 순서로 다이어리 프로젝트를 만들어봤어요. 이전에 스프링으로 구현을 해봤어서 따로 설계는 필요 없었기에 여러 사이트에서 디자인 아이디어를 찾아 AI를 활용하여 Html 템플릿을 만들어보았습니다. 현재까지 구현된 바는 아래와 같아요.
[출처 및 참고] 백엔드를 위한 Django Rest Framework with 파이썬 - 권태형 저
사람들에게 무료로 배포할 수 있는 퀴즈 게임을 만들어보고 싶었어요. 가능하다면 공부하는 사람들에게 도움이 되면 좋겠다, 아니면 연인이나 친구들과 넌센스 퀴즈를 만들어 공유하면 좋겠다 싶어 만들었어요. 작은 미니 pc를 사서 도메인을 구입하고 DNS와 IP를 연결해 사이트를 열어두었습니다. 사이트는 simdev1234.site 여기로 들어가면 무료로 가입 후 퀴즈 게임을 사용할 수 있습니다!:)
퀴즈 게임을 만들고 테스트를 해보면서 애인과 친구들을 위해 퀴즈를 만들어 공유를 했었어요. 예를 들어 아래와 같이, 궁합 테스트를 하는 게임을 만들어서 애인에게 공유를 했었죠.
내가 만든 퀴즈는 다른 사람들과 링크를 공유할 수 있게 만들었기 때문에, 빠른 공유가 가능합니다. 정해진 시간 안에 문제를 풀도록 되어 있기 때문에 타임 압박을 받으며 솔직(?)한 답변을 할 수 있어요.:)
가능하면 쉽고 빠르게. 그러면서도 모두가 재밌게 즐길 수 있는 방향으로 만들어보려 노력했습니다. 무료로 배포하는 거니, 편하게 사용해주시면 좋겠어요. :) 이제 또다른 플젝을 시작해봐야겠군요. 이번에는 파이썬과 Django를 써봐야겠어요. 자바랑 스프링은 너무 물리니, 새로운 시도도 좋겠죠. 그 때까지 다들 행쇼하시고, 다시 보아요~
최근 Open AI의 상업용 API를 통해 일기를 분석해주는 AI 성장일기라는 웹 프로그램을 만들었다. 일기에서 볼 수 있는 핵심 가치, 반복된 사고, 감정 상태를 분석하고, 필요로 하는 다음 행동에 대해 추천하는 식으로 결과를 받았었다. 이 때, 나는 Prompt에 몇 가지 감정 상태에 대한 Scale값을 미리 전달했었는데, 같은 일기에 대해 매번 결과값이 상이한 것을 보았다. 몇몇의 지인들에게 프로그램을 사용하게 해보았더니, "답변이 좀 어색하다."라는 대답을 받았다.
스스로 AI에 대한 상식이 부족함을 느꼈다. 그래서 머신러닝과 인공지능에 대한 강의들을 속성으로 듣고 관련된 책을 찾았다. 실제 머신러닝 강의에서는 아래보다 더 많은 내용을 다룬다. 딥하게 가면 선형대수와 같은 수학에 대한 사전 지식이 필요하고, 학습기들에 대한 개념들도 심층적으로 다룬다. 모든 걸 다 이해할 수는 없었는데, 개념적인 부분만 간단하게 정리해보았다.
인공지능
인공지능이란, 인간의 지능을 모방하여 문제해결을 위해 사람처럼 학습하고 이해하는 기계를 만드는 분야를 말한다. 머신러닝은, 풀어서 기계학습을 말하는 것으로, 인공지능의 한 분야이다. 인간의 학습 능력을 기계를 통해 구현하는 분야를 말한다. 딥러닝은, 머신러닝 중에서도 심층 신경망 기반으로 학습을 하는 방법을 말한다.
머신러닝
머신러닝에서 중요한 것은, "학습"이다. 실생활에서 발생하는 문제를 해결하기 위해 기계를 사용하는데, MNIST(미국 우체국)과 같은 곳에서 제공하는 대량의 Data Set을 통해 충분한 데이터를 사전에 확보하는 것이 중요하다. 그러고 나면 우리는 데이터에 대한 1) 전처리를 하거나, 불필요한 데이터를 축소하는 2) 특징추출을 할 수 있다. 이후로는 어떠한 학습기를 사용해 문제를 해결할 것인가에 대한 고민이 남는다. 어떤 학습기 = 모델을 쓸 거냐에 대해 3) 모델 수립 및 분석을 하고, 4) 모델 평가를 한다. 학습기에 대한 모든 학습이 정상적으로 이루어져 새로운 문제들이 오차 없이 해결 된다면, 5) 배포의 단계를 거쳐 머신러닝 개발을 완료한다.
머신러닝의 기본 요소
머신러닝에서는, 데이터를 "Vector" 단위로 표현한다. Vector는 열벡터라고도 부르는데, 말그대로 N차원의 행렬을 말한다. 데이터의 특성이 무엇이냐에 따라 Vector의 차원은 여러개가 될 수 있다.
x = [1, 1, 1, 0, 0] ==> 이것을 세로로 둔 것을, "열 벡터"라고 한다. 열이 여러 개가 되면 그것을 차원이라고 부른다.
머신러닝의 주제
무엇을 어떻게 학습시킬 것이냐에 따라, 머신러닝의 주제는 달라질 수 있다. 대량의 데이터를 이산적으로 분류하고 싶다면 "분류"를, 시간적인 흐름에 따라 어떤 연관성을 파악하고 싶다면 "회귀"를, 그룹을 나누는 클러스터링을 하고 싶다면 "군집화"를, 원데이터에 불필요한 데이터를 축소하고 싶다면 "특징 추출"을 할 수 있다. 여기서 만약 복잡한 신경망 기술을 활용하게 되면 그건 "딥러닝"에 해당이 된다. 다른 머신러닝 방식과 다르게, 딥러닝을 활용하면 비정형 데이터를 효과적으로 처리할 수 있다.
학습 시스템 관련 개념
목표하고 하는 결과값을 미리 알고 있다면 그것은 "지도 학습"에 해당된다. 그렇지 않다면, 임의의 군집을 나누어 끊임 없이 오차를 줄여가는 방식과 같은 "비지도 학습"을 하게 된다. 두 가지를 섞은 게 "준지도 학습"이다. 이 외에도 파블로그의 개 실험과 같이 강화학습을 통해 학습을 하는 경우도 있다.
딥러닝
심층신경망을 통해 학습을 하는 기술을 말한다. 이때 사용되는 것으로 RNN과 LSTM이 있는데 관련된 내용은 다음과 같다.
기본 순환 신경망(RNN)
RNN은 Recurrent Neural Network의 약자로, Recurrent는 재귀, 반복을 의미한다. 쉽게 말해 이전의 기억을 활용하는 신경망을 말한다. 주식의 시세와 같이 순서 정보를 가지고 있으며 출현 순서가 중요한 데이터를 처리할 때 유용하다. 입력층 - 은닉층 - 출력층으로 구성된 구조가 기존의 MLP(다층신경망)와 비슷하나, 은닉 노드에 가중치를 갖는 순환 엣지가 존재하여 직전에 발생한 정보를 현재의 입력으로 제공한다는 점이 다르다.
입력 → [기억] → 출력
↑ ↓
[기억]
RNN이 가진 단점은, 기울기 소실 문제로 긴 시퀀스에서 초기 정보가 점점 사라진다는 점이다. 그래서 LSTM이 등장했다.
LSTM와 GRU
LSTM은 Long Short-Term Memory의 약자로, 말그대로 장기기억과 단기 기억을 구분하는 신경망을 말한다. 중요한 기억은 오래 기억하며, 불필요한 정보는 삭제하는 방식으로 동작한다. 이것을 단순화한 것이 GRU이다.
LSTM의 경우,
입력 → [망각 게이트] → [입력 게이트] → [출력 게이트] → 출력
↑ ↓
[장기 기억 저장소]
GRU의 경우,
입력 → [초기화 게이트] → [업데이트 게이트] → 출력
RNN은 간단한 시계열 예측에 사용되며, LSTM의 경우 긴 문장을 번역하거나 음성을 인식할 때 사용되고, GRU는 상대적으로 짧은 텍스트를 분류하거나 감정을 분석할 때 유용하다고 한다.
LLM(Large Langauge Model)
LLM은 딥러닝에 기반을 둔 것으로, 자연어 처리 시 언어를 이해하고 생성할 수 있는 언어 모델이다. LLM은 크게 1) 상업용 API와 2) 오픈소스 LLM으로 나뉜다.
상업용 API LLM
Open AI에서 제공하는 상업용 API가 위에 해당된다. 토큰 단위로 비용을 지불하면서 Prompt 명령어를 통해 Data로부터 분석 결과를 받을 수 있다. 이러한 상업용 API는 범용적 언어 생성 능력이 뛰어하다. 그렇기에 단순 검색용으로 적합하지만, 특정 도메인에 특화된 결과값을 받기에는 적절하지 못하다.
오픈 소스 LLM
오픈 소스 LLM은 추가학습을 통해 특정 도메인에 특화된 방식으로 학습을 할 수 있다. 이를 sLLM이라고 부른다.
LLM은 말그대로 대량의 언어 데이터를 활용해 그럴듯한 대답을 만들어내는 데에 특화되어 있으나, 그 정보의 사실 유무에 대해 판단할 능력은 없다. 실제 Open AI의 API를 통해 일기를 분석했을 때, 내 일기를 엉뚱하게 분석하는 것을 종종 보았다. 이에 관해 평가해주었던 교수님들은 AI가 민감한 일기 정보를 부정적으로 분석할 걸 우려하셨다. 예를 들어 우울을 조장하는 듯한 멘트가 나오는 것처럼. 상업용 AI에서 겉만 멀쩡하지만 결과가 온전하지 않게 나타나는 문제를 "환각 현상"이라 부른다. 이를 해결하기 위해 RAG(검색 증강 생성)이라는 기술이 발전했다.
검색 증강 생성 RAG
검색 증강 생성 기술을 쉽게 보면, 마치 도서관 사서와도 같다. 질문을 받으면 관련된 문서나 데이터를 찾아보고, 그 데이터를 토대로 답변을 한다. 일반 LLM이 2년 전에 읽은 책들로만 답변을 한 다면, RAG 시스템은 도서관에서 최신 책을 찾아보고 답변을 해준다. 이런 방식은 최신 제품 정보를 제공하는 고객서비스나, 최신 의학 논문을 참고하는 의료 분야, 현재 법률 정보를 활용하는 법률 자문 서비스 등에 활용될 수 있다.
RAG 시스템에서 중요한 것은 "검색"이다. 검색을 하기 위해서는 검색 데이터를 벡터 DB에 저장하는 과정이 필요하다. 1) 사용자가 검색을 하면 검색 내용을 벡터 DB에 저장한다. 이후 2) 벡터 DB에서 검색을 한 후 요청값에 맞게 프롬프트를 완성한다. 이러한 과정을 겪으면 사실이 아닌 결과값을 사실에 가깝게 변경할 수 있다.
이제 내가 해야할 건 무엇일까?
나는 스프링을 통해서 일기 분석 앱을 만들었었다. 기존의 LLM 관련 강의들을 보면 주로 파이썬으로 이루어진 강의들이 많았는데, 당장 파이썬을 공부하는 것 보다는 기존 앱을 변경하는 방식이 나을 것 같았다. 위대한 Claude에게 한 번 너라면 어떻게 할 거냐 물어보았다. 이 친구가 내게 조언한 건 다음과 같았다.
[1] 프로젝트 개선 방안 - RAG 시스템 구현하기 : 일기 데이터를 벡터화하고, 유사한 감정/상황 패턴을 검색하게 한 뒤, 더 정확한 분석 결과를 제공하라. - 사용자 피드백 시스템을 도입하라 - 감정 분석 결과의 일관성을 확보하라
[2] 추천 학습 경로 - Prompt Engineering 심화 학습 - 벡터 DB 구축 방버 학습 - Spring 에서 AI 통합 방법 학습
가상화 기술은 크게 세 가지로 나뉜다. 1) 호스트 가상화, 2) 하이퍼바이저 가상화, 3) 컨테이너 가상화. 호스트 가상화의 경우, 호스트 OS에 설치 프로그램을 받아 실행하는 것으로 게스트 OS를 쓰는 방식을 말한다. 하이퍼 바이저는, Windows에 딸려있는 Hyper-V 같이 하드웨어에 붙어 있는 가상화 기술을 말한다. 컨테이너는, Docker 같이 각각의 컨테이너로 격리된 공간을 나누고, 호스트 OS의 자원을 공유할 수 있게 한 기술을 말한다. 이번에 설치하는 Oracle Virtualbox는 이 중에서도 호스트 가상화 기술을 사용한 것이다.
[출처] 한빛출판네트워크, 원리부터 이해하는 도커 - 컨테이너, 가상화, 구성요소
호스트 가상화
하이퍼바이저 가상화
컨테이너 가상화
내용
HW에 설치된 호스트 OS 상에 가상화 SW가 설치되고 그 위에 SW 실행을 위한 게스트 OS가 구동되는 방식
특정 OS에 의존하지 않고 하드웨어에 직접 설치되는 구조의 가상화 기술
- 전가상화 : H/W를 완전히 가상화 하는 방식(관리용 DOMO통해 게스트OS들의 커널 요청을 번역하여 하드웨어로 전달)
- 반가상화 : 게스트 OS가 하이퍼콜을 요청
애플리케이션을 동작시키는데 필요한 라이브러리 및 종속 리소스를 함께 패키지로 묶어 생성한 호스트 OS상의 논리적인 구역
장점
게스트 OS가 HW 리소스에 접근하는 것을 제어하고 동기화하기 때문에 호스트 OS에 제약이 없음
오버헤드 비용이 적음, 하드웨어를 직접 관리하여 리소스 관리가 유연함
게스트 OS의 실행에 소요되는 오버헤드가 없어 상대적으로 고속으로 작동
애플리케이션에서 사용하는 미들웨어나 라이브러리의 버전이 상이하여 발생하는 문제를 컨테이너를 통한 격리로 해결
단점
호스트 OS와 게스트 OS의 공존으로 필요이상의 CPU, 디스크, 메모리 사용의 오버헤드 발생
-
-
프로그램
VMWare Workstation, Microsoft Virtual Server, Oracle Virtual Box
VMware ESXi Microsoft Hyper-V Citrix XenServe
Docker
준비
Oracle Virtualbox 및 Mac OS 이미지를 다운로드한다. * 가급적 Mac OS 버전을 13 이상으로 까는 걸 추천한다. Redcat 같은 앱은 버전 13 이상이어야 가능..
[1] Oracle Virtualbox 프로그램 설치 [바로가기] [2] Oracle Virtualbox 프로그램 확장팩 설치 [바로가기] [3] Mac OS 버전 이미지 다운로드 [4] 현재 내 컴퓨터가 가상화 기술을 허용하고 있는지 확인 - 부팅할 때 ESC를 눌러서 세팅화면으로 넘어가서 확인하기
가상머신 생성하기
[1] [새로만들기] 를 눌러 가상 머신을 만든다.
[2] 가상머신의 이름을 작성하고 종류는 Mac OS X, 버전은 Mac OS X (64-bit)
* 버전의 경우, 사용하려는 Mac OS 이미지 버전과 맞는 것을 고르는 게 좋다. 그렇지 않으면 제대로 설치가 안 된다. * 만약, 처음 [새로 만들기]를 누르는 게 아니라면, ISO 이미지를 여기서 추가해줘도 좋다.
[3] 하드웨어의 기본 메모리를 9000 MB 이상, 프로세서를 2개 이상으로 설정한다.
* 실제로 해보면 프로세서 2개도 느렸다. 나는 가상머신 쓸 때 호스트OS로 작업을 안 할 거라, 그냥 4개로 넣어줬다.
[4] 새 하드디스크를 만들어 준다. 파일 형식은 VMDK로 하고 Split into 2GB Parts에 체크를 해준다.
설정 세팅
[1] [시스템] - [마더보드]의 설정을 체크한다. - 플로피 체크해제 - 칩셋 : ICH9 - 포인팅 장치 : USB 태블릿 - EFI 활성화
[2] [시스템]-[프로세서] 에서 PAE/NX 가 활성화 되어있는지 확인
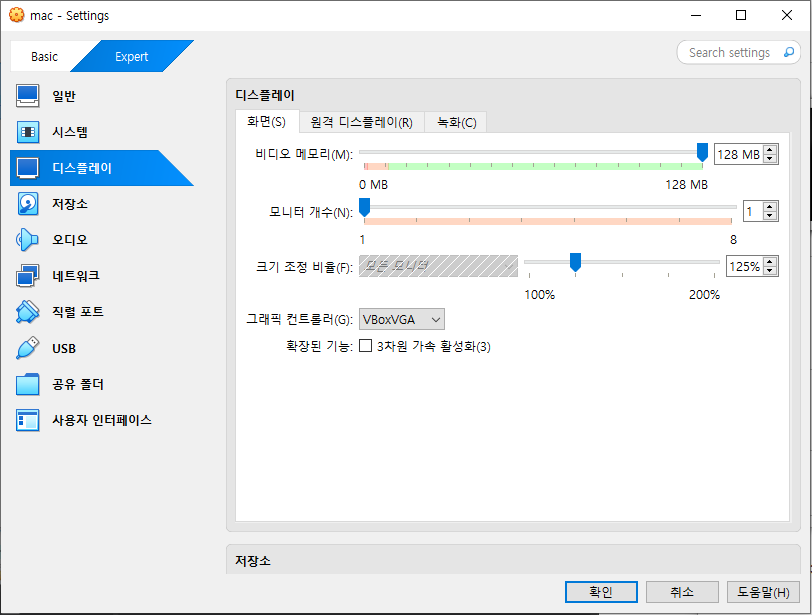
[3] [디스플레이]-[화면] 에서 "비디오 메모리"를 128MB로 수정, 그래픽 컨트롤러도 VBoxVGA를 사용한다.
[4] [저장소]에서 컨트롤러 SATA의 "호스트 I/O 캐시 사용"에 체크
[5] 아래와 같이 ISO 가 먼저 올 수 있게 SATA 포트를 0으로 설정해 준다.
CLI에서 스크립트 실행하기
Virtualbox에서 MacOS를 가상화하기 위해서는 CPU ID, DMI 정보, SMC 설정, CPU 프로필 설정을 해야한다.
[1] Windows에서 CMD창을 관리자 권한으로 실행하고, 아래의 코드를 입력해 설정을 시도한다.
- 어플리케이션을 목적에 따라 여러 개의 독립적인 서비스로 분할하여 개발하고 배포하는 방식
MSA의 특징
- 독립된 각 서비스 마다 고유의 ip와 port를 가진다.
- 각각의 서비스가 분산되어 있기 때문에, 배포와 테스트가 어렵다
MSA를 왜 쓸까?
느슨하게 결합된 서비스들의 모임으로 프로젝트를 구성함으로써, 전체 시스템 구조를 논리적으로 구분해 이해하고,
고가용성(부분 장애가 전체 장애로의 확장을 막음)을 높이며, 분산 처리를 가능하도록 하기 위함
MSA를 편리하게 하기 위한 아키텍처 컴포넌트
스프링 클라우드(Spring Cloud)
분산 시스템의 몇가지 공통된 패턴들을 빠르게 빌드할 수 있도록 다양한 툴을 제공해 준다.
예를 들어, Configuration management(설정 관리), Service Discovery(서비스 검색), circuit breakers(회로 차단), intelligent routing(라우팅), micro-proxy, control bus, short lived microservices and contract testing.
Consumer-driven and producer-driven contract testing
Service Discory란? 왜 쓸까?
클라언트에게 필요한 서비스가 어디에 있는지 빠르게 찾으려고.
서비스를 등록/해제/조회할 수 있는 API를 제공하며, 고가용성이 보장되어야 한다.
Service Registry를 통해 서비스를 관리하며, 지속적인 서비스 상태 모니터링이 가능하다.
- Netflix Eureka, Apache Zookepper 등이 있음
Eureka
Spring Cloud Netflix는 Netflix OSS와 Spring 어플리케이션을 통합해주는 것으로, autoconfiguration 및 Spring 환경과 다른 Spring 프로그래밍 모델과의 binding을 제공합니다. 몇 가지 간단한 Annotation을 사용하면 애플리케이션 내부의 공통 패턴을 신속하게 활성화 및 구성하고, 검증된 Netflix 구성 요소를 사용하여 대규모 분산 시스템을 구축할 수 있습니다. 제공되는 패턴에는 Service Discovery(Eureka)가 포함됩니다. (출처:spring cloud netflix 공식 document)
-> 다시 말해, Netflix OSS를 Spring에서 사용할 수 있도록 해주는 것으로,
-> Netflix는 2007년 DB 문제로 서비스가 중단된 이래 신뢰성이 높고 scale-out한 시스템을 구축하기 위해 Netflix OSS를 만들었다.
-> Netflix OSS는 1) 고가용성(하나가 망해도 다른 하나가 산다), 2) scale-out, 3) easy deploy의 특징을 갖는다.
-> Eureka 또한 Netlfix OSS의 하나로, Service Discovery를 담당하는 모듈을 말한다.
Service Discovery: Eureka instances can be registered and clients can discover the instances using Spring-managed beans
Service Discovery: an embedded Eureka server can be created with declarative Java configuration
Eureka Service Discovery의 용어
- Discovery : 검색
- Registry : 등록 목록
- Eureka Client : 각 서비스에 해당되는 모듈
ㄴ 자기 자신을 Eureka Server에 등록한다.
ㄴ Eureka Server를 통해 다른 Client의 정보를 검색할 수 있다.
- Eureka Server : Eureka Client를 관리하는 서버
ㄴ Eureka Client 정보를 Registry에 등록
ㄴ Heartbeat를 통해 Client가 수행 중임을 확인
Eurkea Service Discovery 흐름의 예시
1. Eureka Client 서비스가 시작될 때, Eureka Server에 자신의 정보를 등록
2. Eureka Client는 Eureka Server로부터 다른 Client의 연결 정보가 등록되어 있는 Registry를 받고 Local에 저장한다.
3. N초마다 Eureka Server로부터 변경 사항을 갱신받는다.
4. N초마다 ping를 통해 자신이 동작하고 있다는 신호를 보낸다. 신호를 보내지 못하면 Eureka Server가 보내지 못한 Client를 Registry에서 제외시킨다
Eureka Service Discovery 사용하기
- Eureka Server
# eureka server port
server:
port: 8761
# MSA module id (eureka)
spring:
application:
name: mindchat
# Eureka server does not need to be included
eureka:
client:
register-with-eureka: false # 레지스트리에 자신을 등록할 것인가 (default : true)
fetch-registry: false # 레지스트리에 있는 정보를 가져올 것인가
service-url: #server의 위치 지정
defaultZone: http://localhost:8761/eureka
- Eureka Client
ㄴ eureka.client.register-with-eureka : 레지스트리에 자신을 등록할 것인가 여부
ㄴ eureka.client.fetch-registry : 레지스트리에 있는 정보를 검색할 것인가 여부
server:
tomcat:
threads:
max: 200 # 생성할 수 있는 thread의 총 개수
min-spare: 10 # 항상 활성화 되어있는(idle) thread의 개수
accept-count: 100 # 작업 큐의 사이즈
다수의 요청이 존재할 때 Spring MVC는 Queue안에 요청 사항을 받아두고, 미리 지정해둔 Thread수에 따라, Thread Pool의 Thread를 사용하여 멀티태스킹을 하게 된다. 이 때, 각각의 Thread는 동기적인 처리를 하게 되는데, 하나의 요청을 받게 되면 응답까지 한 번에 받을 수 있도록 처리하며, 하나의 함수에 대해 return을 받을 때까지 블로킹 처리를 한다.
- 동기적이다 : 호출과 응답이 동시에 이루어진다. (ex. 공을 던지고 받는다) - 비동기적이다 : 호출과 응답이 동시에 이루어지지 않는다. (ex. 기차에 공을 올려 도착할 때까지 기다린다) - 블로킹 : 함수를 콜했을 때 응답을 받기 위해 멈춰있는 상태 - 논블로킹 : 함수를 콜했을 때 응답을 받기 위해 멈춰있기 않고 다음 줄을 실행하는 상태
이 방식의 경우, 정해진 time-slice에 따라 Queue로 이동하며 멀티 태스킹을 하게 되는데, 다수의 Client의 요청에 대하여 DB데이터 응답 시간이 지연될 경우, 해당 시간 동안 손가락을 빨고 기다리는 상황이 발생할 수 있게 된다.
이를 해결하기 위한 방법이 Spring Webflux이다. Spring Webflux는 Node.js와 같이 Event Loop가 돈다. JavaScript는 비동기로 동작을 하는데, 함수를 Stack에 두어 LIFO 방식으로 실행하는 것은 Java와 동일하지만, 함수를 Callback Queue에 또한 넣어둠으로써 Stack이 다 비워졌을 때 FIFO으로 Queue의 함수를 실행하도록 Event Loop를 돈다.
Javascript Event Loop
Webflux 또한 이러한 Event Loop를 사용한다. 10초의 지연 시간이 있는 요청이 있다면 해당 요청에 대한 핸들러(=함수)에게 처리를 위임하고, 처리가 완료되는 즉시 Callback Queue에 Callback을 추가한뒤 Stack을 통해 실행하게 된다. 10초의 지연 시간 동안 처리할 다른 함수가 있다면 해당 함수가 Stack에 두어 실행된다. 이러한 처리 방식을 비동기/논블로킹 처리 방식이라 하며, 이벤트 발생에 대해 반응을 한다하여, Reactive Programming이라고 한다.
이 많은 app들의 endpoint(ip+host+port+path)를 일일히 관리하려면 엄청난 수작업이 필요하고,
각각의 서비스들마다 공통적으로 들어가는 인증/인가, 로깅 등의 기능을 중복으로 작업하는 것에 어려움이 생긴다.
[1] 공통 로직 처리
Gateway를 일종의 Proxy(대리자)로 두게 되면, 각각의 요청사항에 대한 공통 기능(인증/인가 및 로깅)을 편리하게 작업할 수 있다.
[2] Api Routing
라우팅은 네트워크 상에서 경로를 선택하는 프로세스를 의미한다. API Routing이란 동일한 API 요청들에 대해,
각각의 클라이언트나 서비스에 따라 다른 엔드포인트를 사용할 수 있도록 해주는 것을 말한다.
(1) 로드밸런싱
API Gateway를 사용하면 여러 개의 서비스 서버로 API를 분산시켜 주기 때문에 로드밸런서 역할을 한다.
(2) 클라이언트 및 서비스별 엔드포인트 제공
API Gateway를 사용하면 요청을 공통 API로 보내더라도 각 클라이언/서비스별로 엔드포인트를 분산할 수 있다.
(3) 메세지/헤더 기반 라우팅
메세지나 헤더 기반으로 API 라우팅을 할 수 있다. 라우팅에서 요청 API에 대한 메세지를 파싱할 때 많은 파워를 소모할 수 있기 때문에, Restful API를 제공할 경우, Header에 Routing 정보를 두어 Header정보를 파싱하도록하고, Body는 포워딩 할 경우 API Gateway의 부하를 줄여줄 수 있다.
[3] Mediation 기능
(1) 메세지 포맷 변환
클라이언트와 서버가 서로 다른 메세지 포맷을 사용할 때, 이를 적절히 변환시켜 주는 역할을 의미
(2) 프로토콜 변환
내부 API는 gRPC를 사용하고 외부 API는 Restful API를 사용함으로써 내부 API의 성능을 높이면서 범용성을 높일 수 있도록 프로토콜 변환이 가능하다.
(3) Aggregation
서로 다른 API를 묶어서 하나의 API로 제공하는 것을 의미한다. 어떤 요청에 대해 A/B/C모듈 각각의 API를 호출해야할 경우, API Gateway를 사용하면 A/B/C API를 한번에 처리가 가능하다.
Gradle에서 의존성 추가
** 주의 사항1
spring-cloud-starter-gateway-mvc : Spring Mvc 기반 / Servlet API / Blocking I/O 모델 사용 / Tomcat
spring-cloud-starter-gateway : Spring Webflux 기반 / Reative API / Non-blocking I/O 모델 사용 / Netty
** 주의 사항2
spring-cloud-starter-gateway는 Webflux 기반이기 때문에 SpringMVC기반의 라이브러리와 함께 쓸 경우,
"Spring MVC found on classpath, which is incompatible with Spring Cloud Gateway." 메세지가 발생한다.
따라서 spring-boot-starter-web 등의 MVC 기반 라이브러리는 같이 사용하면 안된다.
- Service Discovery는 말 그대로 서비스를 찾아주는 것으로써, 어느 위치에 어떤 서버가 있는지를 찾아준다.
rf. key / value 형태로 서비스를 등록하고 검색할 수 있도록 해준다.
- 넷플릭스 자사의 기술들을 Java Spring 재단에 기부를 하면서 만들어진 것이 Eureka이다.
- Eureka를 쓰려면 먼저 서비스를 등록해야 한다.
- Client에서 요청이 Load Banlancer로 들어오면 Service Discovery가 서비스의 위치를 찾아준다.
2. 프로젝트 환경 구성
[1] 프로젝트 생성
- 마인드챗이라고, 내 마음 속 이야기를 채팅창에 적을 수 있는 플젝을 한 번 만들어보고 싶어서 아래처럼 만들어봤다.
[2] 의존성에서 유레카 서버 하나만 먼저 넣어준다.
- build.gradle의 모습
plugins {
id 'java'
id 'org.springframework.boot' version '3.2.1'
id 'io.spring.dependency-management' version '1.1.4'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
java {
sourceCompatibility = '17'
}
repositories {
mavenCentral()
}
ext {
set('springCloudVersion', "2023.0.0")
}
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${springCloudVersion}"
}
}
tasks.named('test') {
useJUnitPlatform()
}
[3] 메인 클래스에 유레카 서버를 활성화하는 Annotation 추가
@SpringBootApplication
@EnableEurekaServer
public class MindchatApplication {
public static void main(String[] args) {
SpringApplication.run(MindchatApplication.class, args);
}
}
[4] application.yml 작성
# service port (Eureka 서버 포트)
server:
port: 8761
# MSA 각 서비스의 고유 id 부여
spring:
application:
name: discoveryservice
# 마이크로 서비스를 등록하는 역할을 한다.
# Eureka는 서버로서 구동만 하면 되기 때문에 아래 사항을 false로 입력
eureka:
client:
register-with-eureka: false
fetch-registry: false
- 실행 시, 로그에 8761 포트 뜸
main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8761 (http)
- http://localhost:8761 로 들어오면 Eureka Dashboard 화면 보임
피보탈에서 아래에 +3 (Api First, Telemetry(수치화/시각화), Authentication and authorization) 을 더 추가했다.
I. Codebase
One codebase tracked in revision control, many deploys
> 리포지토리에 저장한 각 마이크로 서비스에 대한 단일 코드베이스 / 버전 제어 위함 / 코드는 한 곳에서 배포
II. Dependencies
Explicitly declare and isolate dependencies
> 종속성. 각 마이크로 서비스는 각각의 모듈에 종속적이라 전체 서비스에 영향을 주지 않음
III. Config
Store config in the environment
> 설정
IV. Backing services
Treat backing services as attached resources
> 서비스 지원. 데이터/캐싱/메시징 등을 지원
V. Build, release, run
Strictly separate build and run stages
> 빌드/릴리즈/실행환경을 분리하라. 각 태그 있고 분리되며 자동화된 배포가 이뤄져야한다.
VI. Processes
Execute the app as one or more stateless processes
> 하나의 프로세스는 다른 프로세스와 독립되어야 한다.
VII. Port binding
Export services via port binding
> 포트 바인딩. 각 서비스별로 포트가 달라야한다.
VIII. Concurrency
Scale out via the process model
> 동시성. 하나의 서비스가 여러 인스턴스에 나뉘며 부하 분산 -> 동시성을 가져야 한다.
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
> 확장성. 서비스 인스턴스 등록 및 삭제 / 실행이 쉬워야
X. Dev/prod parity
Keep development, staging, and production as similar as possible
> 개발/운영 분리
XI. Logs
Treat logs as event streams
> 로그를 출력하는 로직을 어플리케이션과 분리해야 한다. (별도의 모니터링)
> Azure 또는 ELK를 사용할 수 있음
XII. Admin processes
Run admin/management tasks as one-off processes
> 적절한 관리. 마이크로 서비스가 어떠한 상태로 사용되며 리소스가 어떻게 쓰이는지
데이터를 정리하고 분석하는 기능을 통해 관리가 가능하다.
5. 모놀리틱 vs Microservice
모놀리틱은 하나에 모든 서비스를 다 넣는다면, MSA는 서비스를 분리해서 개발하고 운영하는 걸 말한다.
docker exec -it -uroot db001 /bin/bash
mysql -uroot -p
mysql > create user 'exporter'@'localhost' identified by 'exporter123' with MAX_USER_CONNECTIONS 3;
mysql > grant PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
- 호스트에서 각각의 exporter 시작 쉘스크립트 실행
docker exec db001 sh /opt/exporters/node_exporter/start_node_exporter.sh
docker exec db001 sh /opt/exporters/mysqld_exporter/start_mysqld_exporter.sh
docker exec db002 sh /opt/exporters/node_exporter/start_node_exporter.sh
docker exec db002 sh /opt/exporters/mysqld_exporter/start_mysqld_exporter.sh
docker exec db003 sh /opt/exporters/node_exporter/start_node_exporter.sh
docker exec db003 sh /opt/exporters/mysqld_exporter/start_mysqld_exporter.sh