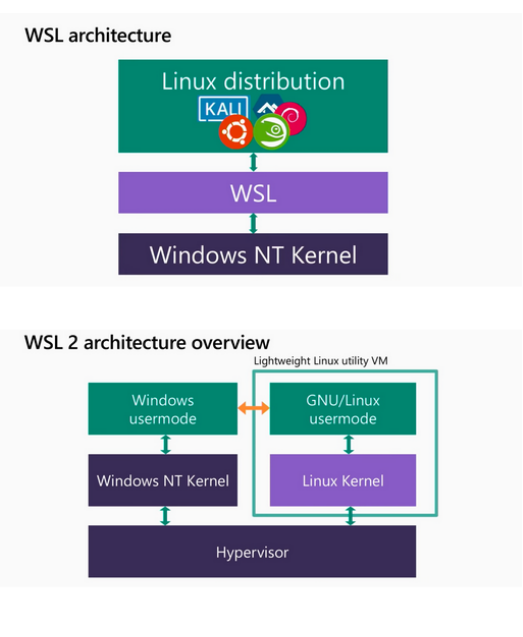
시작하기 전에 - 가상화 기술의 종류 돌아보기
가상화 기술은 크게 세 가지로 나뉜다. 1) 호스트 가상화, 2) 하이퍼바이저 가상화, 3) 컨테이너 가상화.
호스트 가상화의 경우, 호스트 OS에 설치 프로그램을 받아 실행하는 것으로 게스트 OS를 쓰는 방식을 말한다.
하이퍼 바이저는, Windows에 딸려있는 Hyper-V 같이 하드웨어에 붙어 있는 가상화 기술을 말한다.
컨테이너는, Docker 같이 각각의 컨테이너로 격리된 공간을 나누고, 호스트 OS의 자원을 공유할 수 있게 한 기술을 말한다.
이번에 설치하는 Oracle Virtualbox는 이 중에서도 호스트 가상화 기술을 사용한 것이다.

| 호스트 가상화 | 하이퍼바이저 가상화 | 컨테이너 가상화 | |
| 내용 | HW에 설치된 호스트 OS 상에 가상화 SW가 설치되고 그 위에 SW 실행을 위한 게스트 OS가 구동되는 방식 | 특정 OS에 의존하지 않고 하드웨어에 직접 설치되는 구조의 가상화 기술 - 전가상화 : H/W를 완전히 가상화 하는 방식(관리용 DOMO통해 게스트OS들의 커널 요청을 번역하여 하드웨어로 전달) - 반가상화 : 게스트 OS가 하이퍼콜을 요청 | 애플리케이션을 동작시키는데 필요한 라이브러리 및 종속 리소스를 함께 패키지로 묶어 생성한 호스트 OS상의 논리적인 구역 |
| 장점 | 게스트 OS가 HW 리소스에 접근하는 것을 제어하고 동기화하기 때문에 호스트 OS에 제약이 없음 | 오버헤드 비용이 적음, 하드웨어를 직접 관리하여 리소스 관리가 유연함 | 게스트 OS의 실행에 소요되는 오버헤드가 없어 상대적으로 고속으로 작동 애플리케이션에서 사용하는 미들웨어나 라이브러리의 버전이 상이하여 발생하는 문제를 컨테이너를 통한 격리로 해결 |
| 단점 | 호스트 OS와 게스트 OS의 공존으로 필요이상의 CPU, 디스크, 메모리 사용의 오버헤드 발생 | - | - |
| 프로그램 | VMWare Workstation, Microsoft Virtual Server, Oracle Virtual Box | VMware ESXi Microsoft Hyper-V Citrix XenServe | Docker |
준비
Oracle Virtualbox 및 Mac OS 이미지를 다운로드한다.
* 가급적 Mac OS 버전을 13 이상으로 까는 걸 추천한다. Redcat 같은 앱은 버전 13 이상이어야 가능..
[1] Oracle Virtualbox 프로그램 설치 [바로가기]
[2] Oracle Virtualbox 프로그램 확장팩 설치 [바로가기]
[3] Mac OS 버전 이미지 다운로드
[4] 현재 내 컴퓨터가 가상화 기술을 허용하고 있는지 확인 - 부팅할 때 ESC를 눌러서 세팅화면으로 넘어가서 확인하기
가상머신 생성하기
[1] [새로만들기] 를 눌러 가상 머신을 만든다.

[2] 가상머신의 이름을 작성하고 종류는 Mac OS X, 버전은 Mac OS X (64-bit)
* 버전의 경우, 사용하려는 Mac OS 이미지 버전과 맞는 것을 고르는 게 좋다. 그렇지 않으면 제대로 설치가 안 된다.
* 만약, 처음 [새로 만들기]를 누르는 게 아니라면, ISO 이미지를 여기서 추가해줘도 좋다.

[3] 하드웨어의 기본 메모리를 9000 MB 이상, 프로세서를 2개 이상으로 설정한다.
* 실제로 해보면 프로세서 2개도 느렸다. 나는 가상머신 쓸 때 호스트OS로 작업을 안 할 거라, 그냥 4개로 넣어줬다.

[4] 새 하드디스크를 만들어 준다. 파일 형식은 VMDK로 하고 Split into 2GB Parts에 체크를 해준다.

설정 세팅
[1] [시스템] - [마더보드]의 설정을 체크한다.
- 플로피 체크해제
- 칩셋 : ICH9
- 포인팅 장치 : USB 태블릿
- EFI 활성화

[2] [시스템]-[프로세서] 에서 PAE/NX 가 활성화 되어있는지 확인

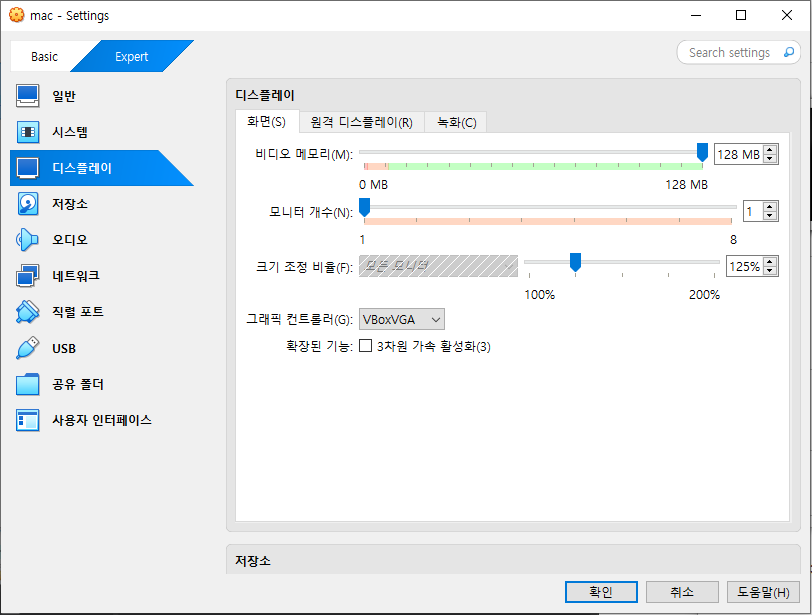
[3] [디스플레이]-[화면] 에서 "비디오 메모리"를 128MB로 수정, 그래픽 컨트롤러도 VBoxVGA를 사용한다.
[4] [저장소]에서 컨트롤러 SATA의 "호스트 I/O 캐시 사용"에 체크

[5] 아래와 같이 ISO 가 먼저 올 수 있게 SATA 포트를 0으로 설정해 준다.

CLI에서 스크립트 실행하기
Virtualbox에서 MacOS를 가상화하기 위해서는 CPU ID, DMI 정보, SMC 설정, CPU 프로필 설정을 해야한다.
[1] Windows에서 CMD창을 관리자 권한으로 실행하고, 아래의 코드를 입력해 설정을 시도한다.
cd "C:\Program Files\Oracle\VirtualBox"
VBoxManage.exe modifyvm "macOS" --cpuidset 00000001 000106e5 00100800 0098e3fd bfebfbff
VBoxManage setextradata "macOS" "VBoxInternal/Devices/efi/0/Config/DmiSystemProduct" "imacOS19,1"
VBoxManage setextradata "macOS" "VBoxInternal/Devices/efi/0/Config/DmiSystemVersion" "1.0"
VBoxManage setextradata "macOS" "VBoxInternal/Devices/efi/0/Config/DmiBoardProduct" "macOS-AA95B1DDAB278B95"
VBoxManage setextradata "macOS" "VBoxInternal/Devices/smc/0/Config/DeviceKey" "ourhardworkbythesewordsguardedpleasedontsteal(c)AppleComputerInc"
VBoxManage setextradata "macOS" "VBoxInternal/Devices/smc/0/Config/GetKeyFromRealSMC" 1
[2] 만약, 부팅 중에 "bdsdxe failed to load boot0001 uefi vbox cd-rom vb1-1a2b3c4d" 에러가 나타난다면 아래를 추가적으로 입력한다. 미리 에러를 막고 싶다면 그냥 [1]에서 같이 입력하는 방법 추천.
VBoxManage.exe modifyvm "macOS" --cpu-profile "Intel Core i7-6700K"
시작하기
Apple 화면이 뜨면 이제 설치를 해주면 된다.
[1] [시작하기]를 눌러서 실행한다.

Apple 화면이 잘 뜬다면 당신은 이제 80% 성공.

[2] Mac OS 설치 전에, [유틸리티] - [디스크 유틸리티]에서 [보기] 버튼을 클릭, "모든 장치 보기" 또는 "Show All Devices" 선택

[3] 왼쪽 사이드 바에서 VBOX HARDDISK Media를 선택 (최상위 디스크 선택), 상단의 "지우기" 버튼 클릭
- 이름: Macintosh HD (원하는 이름)
- 포맷: APFS
- 구성: GUID 파티션 맵
- "지우기" 클릭
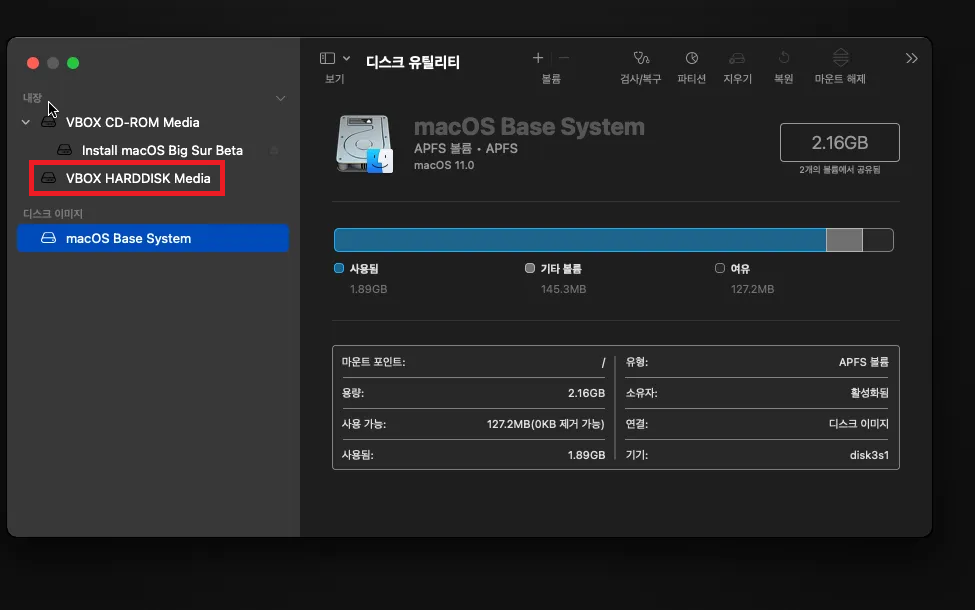
[4] 아래와 같이 내가 설치하고자 하는 디스크 상세 정보가 잘 나오면 됨

[5] 다시 앞으로 돌아가서 Mac OS 설치를 시작한다.
'Computer Science > OS' 카테고리의 다른 글
| [OS] WSL을 통해 윈도우 환경에서 리눅스 사용하기 (1) | 2023.12.25 |
|---|---|
| [소프트웨어 공학] 소프트웨어 공학 및 현업 프로세스 (1) | 2022.09.05 |
| [네트워크] 네트워크의 기초 정리 (0) | 2022.08.28 |
| [시스템 소프트웨어] 쉘스크립트 (0) | 2022.08.21 |
| [시스템 소프트웨어] 리눅스의 기본 명령어 (0) | 2022.08.15 |