■ 큐란?
- FIFO (First in First Out) 방식으로 데이터를 입출력
- 현실 세계의 큐 예 )
티켓 판매기에서 대기하고 있는 사람들,
일방통행 도로의 차동자들, 인쇄기의 인쇄 순서, CPU의 테스크 스케줄링
- 큐의 한계 :
1) front부터 삭제되며, 삭제된 공간을 다시는 사용하지 못한다.
2) (배열을 사용할 경우) 큐의 크기가 정해지기 때문에 rear가 더 움직이지 못한다.
(-> 이 부분은 자바에서는 동적관리 객체인 LinkedList로 해결했다)
- 큐의 한계를 보완 : 원형 큐, 우선순위 큐
■ 큐의 내부 구조
- 유투브의 영상에 나와있는 튜토리얼에 따라 큐를 구현해보았다.
https://www.youtube.com/watch?v=W3jNbNGyjMs&list=PLjSkJdbr_gFZL2BNnGLvTgMYXptKGIyum&index=2
☞ 확인 사항
- 큐는 데이터를 넣을 때 마지막에 넣고, 꺼낼 때는 앞에서부터 꺼낸다
(1) offer을 할 때는 : REAR가 가리키는 것이 있을 때 ) REAR의 NEXT에 연결
FRONT가 가리키는 것이 없을 때(= 저장된 데이터의 사이즈가 0) )
FRONT와 REAR가 모두 null임을 명시한다.
(2) poll을 할 때는 : FRONT가 가리키는 것이 없을 때 ) 꺼낼 수 없으므로 예외 (NoSuchElementException)를 발생
FRONT를 꺼낸 뒤 FRONT->NEXT를 FRONT로 변경
만약에 새로운 FRONT가 가리키는게 없을때(= 저장된 데이터의 사이즈가 0)
FRONT와 REAR가 모두 null임을 명시한다.
※ 자바의 경우 큐는 인터페이스며, LinkedList가 이를 구현하고 있다.
아래의 실제 자바 Queue메소드는 LinkedList에서 사용 가능하다.| 실제 자바 Queue 메소드 | 구현객체의 메소드 | 내용 |
| offer(data) | add(data) | 데이터 추가 |
| poll() | remove() | 가장 앞 데이터 꺼내기 |
| peek() | peek() | 가장 앞 데이터 읽기 |
| isEmpty() | isEmpty() | 비어있는지 확인 |
☞ 구현 하기
import java.util.NoSuchElementException;
class Queue<T>{
class Node<T>{
private T data;
private Node<T> next;
public Node(T data) {
this.data = data;
}
}
private Node<T> first;
private Node<T> last;
public void add(T item) {
Node<T> t = new Node<T>(item);
if (last != null) {
last.next = t;
}
last = t;
if (first == null) {
first = last;
}
}
public T remove() {
if (first == null) {
throw new NoSuchElementException();
}
T data = first.data;
first = first.next;
if (first == null) {
last = null;
}
return data;
}
public T peek() {
if (first == null) {
throw new NoSuchElementException();
}
return first.data;
}
public boolean isEmpty() {
return first == null;
}
}//end class Queue
■ 큐 알고리즘 예제
https://www.acmicpc.net/problem/2164
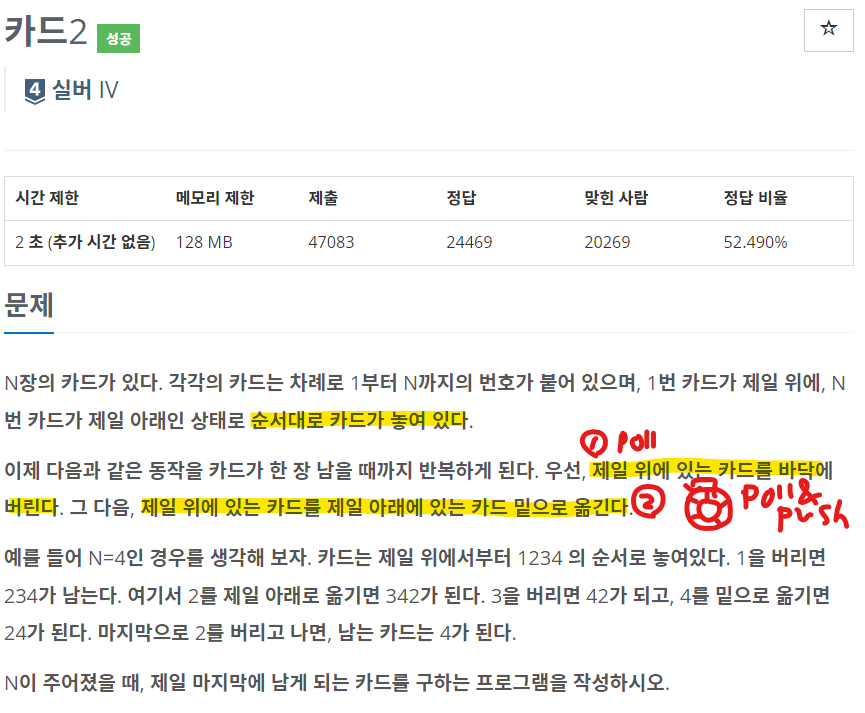
☞ 계획 수립
| [1] LinkedList를 사용하여 데이터를 하나씩 넣어준다. [2] 반복문을 통해 [1] poll [2] poll & offer을 반복한다. |
☞ 계획 수행
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.LinkedList;
public class Ex01_2164_카드2 {
public static void main(String[] args) throws Exception{
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(reader.readLine());
LinkedList<Integer> list = new LinkedList<Integer>();
//순서대로 1~N값 입력
for (int i = 1; i <= N; i++) {
list.offer(i);
}
//버리고, 밑으로 내리는 것 반복
while (list.size() != 1) {
list.poll(); //첫번째로 꺼낸 것은 버린다.
list.offer(list.poll()); //두번째로 꺼낸 것은 가장 마지막에 넣는다.
}
System.out.println(list.peek());
}
}- 여기까지는 문제가 어렵지 않았다.. 그런데 아래의 문제들을 만난 뒤 당황..
■ 원형 큐 (Circular Queue)의 원리를 사용한 알고리즘 문제
- 원형 큐의 개념 : 큐를 원형의 구조처럼 한 바퀴를 돌리며 사용하는 방식

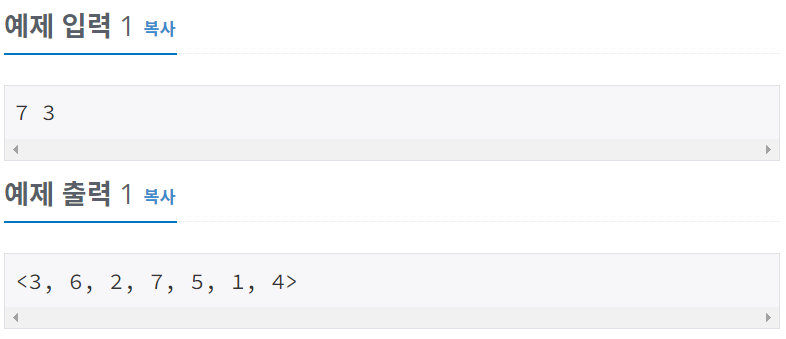
☞ 계획 수립
| [1] LinkedList를 사용한다. [2] 이중 루프를 돌려, - 바깥에서는 큐가 빌 때까지 반복, - 안쪽에서는 K번째 전까지는 poll & offer을 반복하고, K번째에는 poll을 한다. [3] 출력은 StringBuffer를 사용한다. |

☞ 계획 수행
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.LinkedList;
import java.util.Queue;
import java.util.StringTokenizer;
public class Ex02_11866_요세푸스문제1_원형큐사용 {
public static void main(String[] args) throws Exception{
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
StringBuffer buffer = new StringBuffer();
StringTokenizer token = new StringTokenizer(reader.readLine());
int N = Integer.parseInt(token.nextToken());
int K = Integer.parseInt(token.nextToken());
//1~N까지의 데이터를 담을 연결리스트
Queue<Integer> queue = new LinkedList<Integer>();
//1~N까지 데이터 채우기
for (int i = 1; i <= N; i++) {
queue.offer(i);
}
buffer.append("<");
int count = 0;
//큐가 더 이상 아무것도 없을 때까지 반복
while (!queue.isEmpty()) {
//K보다 작을 때까지 poll&offer을 반복
for (int i = 1; i < K; i++) {
queue.offer(queue.poll());
}
//K번째에 poll해서 buffer에 저장
if (count == 0) {
buffer.append(queue.poll());
count++;
continue;
}
buffer.append(", ").append(queue.poll());
}//end while
buffer.append(">");
System.out.println(buffer);
}
}
>> 결과
7 3
<3, 6, 2, 7, 5, 1, 4>▼ 처음에 일반큐 + 배열 + 커서변수를 사용해서 예제를 풀었었다.
그렇게 하니 코드도 길고 내가 적고도 다른 사람에게 설명할 수 없는 코드가 만들어졌다.
스터디 때 다른 팀원분이 원형큐에 대해 설명해주셔서 알아보고 다시 작성을 해보았는데
원형큐를 사용하니 메모리 사용량은 더 많았어도 시간은 더 준 걸 볼 수 있었다.

[참조]
'Computer Science > Algorithm' 카테고리의 다른 글
| [정렬] 병합정렬(Merge Sort) (0) | 2022.05.11 |
|---|---|
| [정렬] 퀵 정렬(Quick Sort) (1) | 2022.05.10 |
| [자료구조] 스택 (0) | 2022.04.18 |
| [검색] 선형탐색과 이진탐색 (0) | 2022.04.12 |
| [자바의 정석] 스택과 큐 (0) | 2022.03.30 |